Forgetting on Purpose: Generalization as the Quality Criterion for Small-Dataset LoRA Fine-Tuning
Abstract
A LoRA that reproduces its training images perfectly is not a well-trained model. It is a memorization device. This article argues that generalization within the trained concept is the right quality criterion for small-dataset LoRA fine-tuning, and proposes a five-tell diagnostic framework — base capability degradation, concept narrowing, caption rigidity, entanglement leak, and visual signature reproduction — for identifying when a LoRA has crossed from learning into memorization. We then describe a chained training schedule we use in our own work, which rotates through dataset subsets before reintroducing the full combined dataset for a final consolidation phase. This methodology has roots in early Stable Diffusion 1.5-era practitioner trainers, where dataset switching was first-class in the UI; in modern trainers it must be reconstructed manually. We report a paired A/B run on Qwen-Image at two scales — a 244-image illustration style LoRA and a 27-image character LoRA — comparing chained training against a monotonic straight-baseline twin under matched conditions. Both runs produce competent results that pass the five-tell diagnostic without obvious failure on either side, and the hyperparameter recipe we use proves itself viable for Qwen-Image at these scales. We observe specific signals of chained-side flexibility advantages, but the gap is not dramatic enough at these dataset sizes to claim a general methodological advantage from this experiment alone. The natural next test is at smaller and harder dataset sizes where overfitting is more likely to surface; we identify that as the experimental program this position paper opens onto rather than closes.
This is a methodological position paper. Quantitative validation is offered as future work.
1. Introduction
A LoRA that reproduces its training images perfectly is not a well-trained model. It is a memorization device wearing a trained model's clothes.
The small-dataset LoRA training community has converged on a set of practical hyperparameters — rank and alpha values, learning rates, EMA decay, caption dropout — but has not converged on what well-trained actually means. Some practitioners aim for maximum fidelity to training images: a generation should be indistinguishable from a held-out training-set image. Others aim for maximum prompt flexibility: the trained concept should compose cleanly with arbitrary scene descriptions. These are different goals, and the community lacks a shared criterion for choosing between them.
This article proposes that generalization within the target concept is the right quality criterion. A LoRA that perfectly reproduces its training set but cannot generalize across pose, framing, lighting, or composition within its target concept has failed at the only thing fine-tuning is supposed to deliver beyond the dataset itself. We argue this is not aesthetic preference but a definitional claim: a model that does not generalize has not learned, regardless of how visually accurate its individual outputs look.
This paper aims to make three contributions:
- A practitioner-readable organization of established failure modes — the five tells. Each tell has its own academic name and citeable failure-mode literature; the contribution here is grouping them into a single diagnostic that maps onto what a practitioner can actually read off a comparison grid.
- A position on quality criterion — that generalization within the concept is the load-bearing measure of training quality, and that the five tells collectively operationalize what to look for.
- A practitioner-history retrospective on a training methodology — chained dataset rotation with final reintroduction — that was once first-class in early diffusion trainer UIs, has not propagated forward to modern toolchains, and which, in a paired A/B run we describe in §6, is performing better than its monotonic counterpart. We surface this observation as worth investigating, not as a recommendation to adopt.
This is Part 1 of a multi-model methodology series. Part 2 will examine the same thesis under additional base model architectures. Part 3 will extend the framework toward video-LoRA training for hand-drawn animation physics.
2. Why Hand-Drawn Illustration Is Hard for Diffusion Models
Before describing failure modes in fine-tuning, we need to establish why hand-drawn illustration in particular is theoretically more prone to them. This section summarizes findings we have collected in earlier internal research and points the reader to the underlying literature for depth.
2.1 The organic-deterministic spectrum
Latent diffusion models do not treat all styles equally. There is an axis along which painterly content is native to the denoising process, and hand-drawn line-art content is misaligned with it. Painterly styles — oils, watercolors, gouache — are low-frequency dominant: their compositions are built from smooth gradients, blended fields, and continuous tonal transitions. These properties match how denoising operates.
At the other end of the same axis: hand-drawn line art and animation, which are high-frequency dominant. Their compositions live in the gradient discontinuities — line pressure variation, hatching, hand-driven irregularities, ink edges. These features fight the denoising process rather than ride it. Pixel art lies at a further extreme of determinism that conflicts with continuous latent representations.
Other style families fall predictably along this axis and are worth flagging as candidates for future testing of the same hypothesis. Toward the low-frequency end: oil painting, gouache, watercolor wash, sumi-e ink wash, color field painting — all dominated by continuous tonal transitions. Toward the high-frequency end: etching and engraving, halftone and risograph print, stippling, woodcut and linocut prints, fine ink hatching. Pixel art is the deterministic-grid extreme. Photography sits in the middle, leaning to whichever frequency band its subject and lighting dictate. Whether the chained-vs-monotonic training behavior we describe in §6 differs predictably across these style families is an open question and a direct next experiment.
2.2 Theoretical grounding
Three established results converge on the same prediction.
Diffusion is spectral autoregression. Dieleman (2024) characterizes diffusion models as denoising in frequency order — low frequencies first, high frequencies last [1]. Painterly content is low-frequency dominant, so painterly styles are recovered early and stably in the denoising trajectory. Hand-drawn content is high-frequency dominant; its essential features appear late in denoising, after the model has already committed to a composition that may not accommodate them.
VAE compression compounds the penalty. Yao et al. (CVPR 2025) demonstrate that the latent space used by modern diffusion models is itself a high-frequency-discarding compression [2]. High-frequency styles lose information twice — once in VAE encoding, once in diffusion's spectral bias. By the time a sketch style LoRA is trying to teach the model line quality, both the latent representation and the denoising trajectory are in opposition.
Line art specifically. Recent work (LineArt, 2024) shows that line art requires dedicated frequency-aware handling to be reliably generated by diffusion models at all [3]. Standard fine-tuning approaches that work for painterly styles routinely produce blurry, smoothed-out outputs when applied to line-art datasets.
2.3 Implication for LoRA fine-tuning
The three points below are theoretical risk profiles drawn from the spectral-bias and VAE-compression literature in §2.2, not empirical claims. Hand-drawn LoRAs need to push the base model against its priors. We expect this to make them:
- Harder to train — the LoRA needs more parameter movement to overcome the prior.
- More prone to overfitting — because the only way to overcome the prior is to commit hard to training-set statistics.
- More likely to exhibit the failure modes we describe in §3.
We have not benchmarked every illustration LoRA against every painterly LoRA, and we do not claim that every hand-drawn LoRA exhibits these risks more severely in practice. What this risk profile does justify is the choice to apply more anti-overfitting precaution in this domain than community defaults assume — which is what we do, and what we describe in §5.
3. The Five Tells: A Diagnostic Framework
Overfitting is often discussed as a single phenomenon. It is not. In LoRA fine-tuning, overfitting splits into at least five distinct failure modes, each with its own academic name in the recent literature, its own detection method, and its own consequence at inference time. Calling all of them "overfitting" is the imprecision that lets bad models look good — and lets practitioners ship them without realizing what they've shipped.
We name and operationalize the five tells below. Each is a citeable failure mode; collectively, they are how we read a LoRA's actual training state independent of fidelity to specific training images.
Each tell is presented as a diagnostic question to ask of a comparison grid, defined in prose only. Specific empirical instances from our own paired runs — where they surfaced cleanly — are reported in §6 alongside the relevant findings. Not every tell produced a clean failure example in our data, and we deliberately do not illustrate them with synthesized or mocked-up failures; the framework's value is the question it asks, not a curated gallery of breakage.
3.1 Tell #1 — Base capability degradation
Definition. LoRA-applied generation of off-distribution prompts degrades versus the base model. The fine-tune has consumed capacity that the base model previously used for unrelated generation.
Academic name. Open-world forgetting (Heng & Soh, 2024) [4], or concept-agnostic overfitting (Infusion, ACM MM 2024) [5]. Heng & Soh build a Color Drift Index over CIE chromaticity and observe accuracy drops above 60% on classes unrelated to the customization concept across DreamBooth and Custom Diffusion. Infusion measures the same phenomenon via latent Fisher divergence on non-customized concepts.
Detection. Compare LoRA-applied generations to no-LoRA generations on prompts unrelated to the trained concept. If the LoRA-applied output degrades the prompt that has nothing to do with the LoRA's subject, base capability has been damaged. The no_lora baseline row in any comparison grid is the operational form of this test.
Why it matters. A LoRA that breaks the base model is unusable in any pipeline that mixes LoRAs or that wants to retain access to the model's underlying capabilities. It is the most strictly defined failure mode of the five and the one most directly responsible for the academic catastrophic forgetting term.
Example description. In a comparison grid, the failure surfaces in the no_lora baseline row versus late-checkpoint LoRA rows on prompts unrelated to the trained concept. The baseline row renders the prompt correctly; later LoRA rows render the same prompt with quality drops — washed colors, missing scene elements, broken composition, or unexpected visual artifacts that have nothing to do with the LoRA's subject. The fingerprint of Tell #1 is that the degradation tracks the LoRA's training duration, getting worse at later checkpoints.
3.2 Tell #2 — Concept narrowing (mode collapse)
Definition. Output variance falls below prompt variance. The LoRA reproduces a narrow template regardless of what the prompt actually asks for. Eight diverse prompts produce eight visually similar outputs.
Academic name. Concept-specific overfitting (Infusion, ACM MM 2024) [5]; the image-similarity / text-similarity tradeoff in T-LoRA (AAAI 2026) [6]. T-LoRA shows that fine-tuning during the noisiest denoising timesteps reinforces background and compositional elements from the training data, narrowing the LoRA's effective output distribution. AutoLoRA (2024) [7] approaches the same phenomenon via automated rank selection.
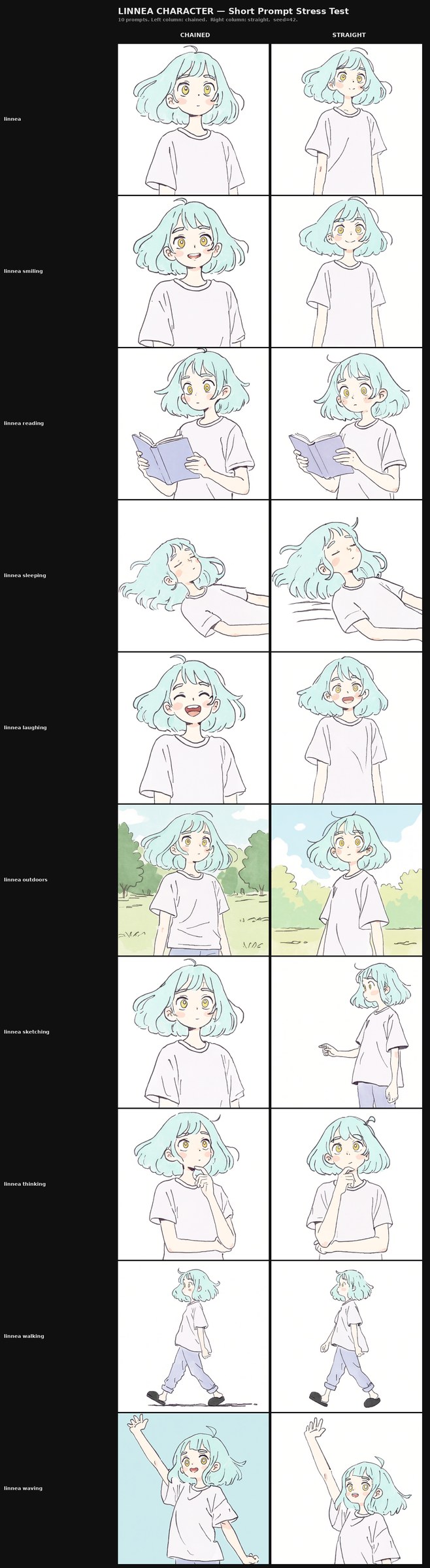
Detection. Vary the prompt parameters that should vary the output — pose, expression, framing, scene context, lighting. If outputs do not vary, the concept has collapsed to a fixed point. A grid with diverse prompt columns and matched seeds is the cheapest form of this measurement. Varying the random seed at a fixed prompt is the complementary form, and is the diagnostic the §6.3 seed-variance test uses.
Why it matters. A LoRA that ignores prompt diversity is uncontrollable. It is also the most common failure mode in our experience and the one most directly responsible for "this LoRA only makes one kind of image" complaints in practitioner communities. Worth noting: the fact that LoRAs exist as an external delta on top of the base model is part of what allows this failure to be partially papered over at inference — which is why model cards commonly recommend strengths of 0.8 or 0.9 rather than 1.0. That is a hack. LoRAs are themselves a hack. But a model that requires its strength to be reduced at inference to behave is not, strictly, a well-trained one — it is a model whose training endpoint was past the useful range, with the strength dial used to walk it back.
This failure also surfaces at the base-model level, not only in LoRA fine-tunes. Figure 1 in §4.1 shows Qwen-Image rendering four hyper-consistent silver-haired anime girls with round glasses across four different seeds on a minimally-specified anime portrait prompt — a Tell #2 signature inherent to the base prior, which any downstream LoRA built on this foundation will inherit unless training specifically pulls against it.
Example description. In a comparison grid with prompts that should produce varied outputs — different poses, framings, expressions, scene contexts — the late-checkpoint LoRA rows produce outputs that look visibly similar across columns. The trained subject keeps appearing in the same pose, the same framing, or the same lighting setup. In the seed-variance form of the test, a single prompt rendered with four different seeds produces a 2×2 of near-identical outputs instead of four distinct ones. We surface a concrete instance of this from our paired runs in §6.3.
3.3 Tell #3 — Caption / token rigidity
Definition. The concept only fires on training-time caption phrasings; paraphrases break it. The LoRA has not learned the concept abstractly — it has learned a narrow mapping from specific token sequences to specific output regions.
Academic name. Caption-conditioned identity binding failure; related to the identity-prompt consistency literature in T-LoRA and the prior-preservation framing of DreamBooth (Ruiz et al., 2022) [8]. The failure surfaces when the LoRA's trained binding to specific captioning phrasings is brittle to alternative natural-language descriptions of the same concept.
Detection. Take a prompt that produces a successful LoRA output. Paraphrase it. Test whether the trained concept survives. If "linnea smiling" produces the character but "a happy linnea" or "linnea looking pleased" do not, the LoRA's identity binding is rigid. In our experience, caption-token rigidity often shows up in LoRAs trained with too-high learning rates and too-low ranks — it is a tell for an overoptimized training pipeline, not just an overlong one.
Why it matters. Rigid LoRAs cannot be composed with other concepts or prompted naturalistically. They become fragile gadgets that only work under specific incantations — which limits their utility as production assets.
Example description. The trained concept fires reliably when prompted with the exact caption phrasings used during training, but a paraphrase produces unrecognizable or significantly weaker output. A grid built by rendering the same target idea through training-phrasing versus paraphrased-phrasing shows the LoRA's effect vanishing or degrading as the prompt drifts from the training caption vocabulary. The failure is binary on the trigger side — present at training phrasings, absent at paraphrases — rather than a smooth degradation.
3.4 Tell #4 — Entanglement leak
Definition. The LoRA's trained concept appears unbidden in unrelated prompts. The fine-tune has fused the concept with the LoRA itself rather than with its trigger condition, so the concept leaks into outputs where it was never requested.
Academic name. Concept entanglement in DreamBooth-style customization; closely related to the prior-preservation motivation of DreamBooth and to the entanglement failure modes documented in ConceptGuard (Guo & Jin, CVPR 2025) [10]. The base-model prior has been globally biased toward the trained concept rather than locally specialized to its trigger.
Detection. Use stress prompts in unrelated contexts. If the trained character appears in a kitchen-interior DSLR prompt that contains no character reference, the LoRA cannot be turned off. The original v1 linnea grid in this work included exactly such an adversarial prompt for this purpose, and the v3 arc retains it as the p7_adversarial column.
Why it matters. A LoRA that cannot be selectively activated is harder to use in mixed pipelines or in commercial workflows where prompt control matters. This is a lesser issue in practice today than it once was, since current community practice tends to load only the LoRA(s) needed for a given concept rather than stacking many at once. Even so, the lead author's working hypothesis is that the deeper cause of entanglement leak is that text tokenization is not a fully clean signal for image conditioning — and that some part of the leak we see in fine-tuned diffusion models is downstream of that mismatch rather than of training pathology per se. This is an active area of our own investigation.
Example description. A prompt that has nothing to do with the trained concept renders cleanly at the no_lora baseline but progressively pulls in elements of the trained concept at later LoRA checkpoints. An architectural-interior prompt starts rendering the trained character's face on a person who was never described; a non-character scene starts inheriting the trained style on objects that have no reason to wear it. The fingerprint is unintended re-appearance of the LoRA's subject or signature in contexts where the prompt did not call for it.
3.5 Tell #5 — Visual signature reproduction
Definition. Identifiable artifacts from the source dataset appear consistently across generations — recurring compression noise, specific lighting hooks, particular compositional angles, idiosyncratic background patterns. The LoRA has not learned the concept or the concept has not been clearly communicated during training; it has learned the dataset. In our experience this most often shows up when training proceeds with rigidly templated prompts or no prompts at all — and it is much more prevalent in older base-model architectures (SD-class) than in modern ones, since the move to dual text encoders with T5 has substantially reduced how often we see this failure in practice.
Academic name. Memorization in the formal sense — verbatim or near-verbatim reproduction of training distribution properties. Studied across multiple recent works on diffusion model memorization, and operationalized in the open-world forgetting literature (Heng & Soh, 2024) [4].
Detection. Inspect many generations, especially across diverse prompts. Watch for recurring signatures that should not be present given the prompt content — e.g. the same studio lighting setup appearing in fantasy and indoor and outdoor and sci-fi scenes alike. The grid format makes this visually cheap.
Why it matters. Visual signature reproduction is the most visible indicator that the LoRA has memorized rather than learned. It is also the most direct argument against a fidelity-first quality criterion — fidelity is preserved here, but the model is producing the same artifact patterns regardless of context, which is the opposite of generalization.
Example description. Across diverse prompts that share no compositional logic — an interior, an outdoor landscape, a vehicle scene, a closeup portrait — recurring visual signatures from the training distribution surface in all of them. The same lighting setup, the same camera angle, the same background pattern, or the same compositional cliché appears regardless of what the prompt is actually asking for. The fingerprint is consistency across prompts that should not be consistent — and the simplest way to read it is to scan a late-checkpoint row of a diverse-prompt grid and ask whether anything recurs that has no business recurring.
3.6 The framework as a whole
The five tells are not orthogonal. A LoRA that exhibits concept narrowing typically also exhibits visual signature reproduction; a LoRA with entanglement leak often also has base capability degradation. They correlate because they share underlying causes — most fundamentally, parameter commitment to training-set statistics in excess of what the concept abstraction warrants.
We do not claim the five are exhaustive. Other failure modes have been documented in the literature — exposure bias, identity drift across multi-character prompts, sampler-conditioned brittleness. We claim only that the five we describe are collectively sufficient to identify the most common cases of overfitting-as-memorization in small-dataset LoRA fine-tuning, and that they map cleanly onto what a practitioner can read off a comparison grid without instrumentation.
In practice, the cheapest and most effective way to read all five tells is to generate a comparison grid: rows of checkpoints, columns of diverse prompts, a no_lora baseline row at the top. Quantitative metrics for each tell — CLIP-score variance, color drift indices, output entropy — are a natural upgrade path for a more rigorous follow-up, but the grid is sufficient for the framework itself.
4. Generalization as the Quality Criterion
This section states the position the article is putting in the sand. It does not depend on any specific methodology; it is a claim about what well-trained should mean.
4.1 The position
A LoRA, and arguably a foundational model, is only well-trained if it preserves generalization within the concept it was fine-tuned on. Overfitting that produces a rigid memorization device is at least partially a failure mode regardless of how visually accurate individual generations look. A LoRA is not well trained if it only reproduce training data faithfully but cannot generalize across pose, framing, lighting, or composition within its target concept.
The foundational-model extension matters because we already see this failure pattern in some open-weights base models. In Qwen-Image the authors observed a biased when generating a consistent anime girl character — a single low description prompt with variant seed produced the same character with slight changes across multiple generations. By the criterion stated above, that bias is a failure mode in the same sense the five tells describe. It is not plausibly attributable to a lack of inherent generalization at foundation-model scale; the underlying pretraining dataset is far too large for that to be the bottleneck. Our reading is that this kind of bias is more often introduced downstream — during the supervised fine-tuning passes intended to improve overall model performance — and then surfaces as a sudden style attractor in an otherwise well-balanced model. Alternatively, this bias may exist prior to supervised fine-tuning; it's possible that the concepts that the model has become more overfit to, such as this particular anime girl characterization, were influenced by lower noise dominant areas of the dataset that converged more quickly than their high noise counterparts within the same contextual range. Both readings are hypotheses our chained-vs-monotonic program is set up to probe in future work.
Scope of this article. The paired runs we report were conducted on Qwen-Image, and our quantitative discussion is bounded to that base model. Informal practitioner observation across the other modern base models the authors have trained against — including Flux and the SDXL successor generation — suggests that qualitatively similar attractor patterns surface on each: every base model we have worked with has its own style-specific bias-failure subsets, where downstream LoRA conditioning is dominated by the base prior on particular prompt shapes. The specific content of those attractors varies between models (Qwen's anime-girl bias is not Flux Klein's bias, which is not SDXL's), but the structural pattern — prompt-shape combinations that activate latent SFT-introduced style commitments — appears general across the model families we have worked with.

p1_anime_girl row at top is the empirical handle on the foundational-bias hypothesis introduced above: four hyper-consistent silver-haired anime girls with round glasses across four different seeds, on a prompt that asked only for "close-up portrait of a young woman with short messy silver hair and round glasses, anime style." This is a base-model-level Tell #2 signature on a particular prompt-shape combination — the bias is sitting in the foundation, before any LoRA is applied, and it surfaces as near-identical outputs across seeds where seed variation should produce different characters. The other anime prompts (denim-jacket scene, comic page, risograph cat) produce visibly varied outputs across seeds; the bias is prompt-specific, not universal. The linnea-prompt rows below generate varied illustrated characters because the trained-character token has no learned binding in the base model; these rows are the no-LoRA control for the linnea seed-variance test reported in §6.3.
4.2 Why memorization is not learning
A LoRA that perfectly reproduces its training set has not learned the concept. It has learned a narrow function from specific prompt tokens to specific output regions of latent space. Learning a concept means inferring a generative function that interpolates across the training distribution and extrapolates within the concept manifold — that produces images you did not show the model that nonetheless belong to the same concept.
Memorization fails this test. There is no concept abstracted; there are only instances stored. A LoRA that can only reproduce training images is structurally equivalent to a content-addressable image database — and the database is cheaper, faster, and easier to inspect.
This distinction is the original motivation for the prior-preservation loss in DreamBooth (Ruiz et al., 2022) [8]. The DreamBooth authors recognized that fine-tuning a generative model on a small subject dataset would, by default, collapse the model's generative capacity into the subject — and added an auxiliary loss to penalize that collapse. The position we are stating is the same insight, generalized: every small-dataset LoRA or fine-tune faces this risk, and the choice to ignore it produces models that look impressive on training prompts and fail on everything else.
4.3 Why "looks like the training data" is not the win condition
The intuitive appeal of fidelity-first training is direct: the training images are the only ground truth the LoRA has. Reproducing them appears to demonstrate that the model has learned. But this confuses the easy half of training (memorizing what you have seen) with the hard half (producing what you have not).
The hard half is the entire reason fine-tuning exists. If we wanted only the training images, we could publish the training images. The fine-tune's value is in everything between and beyond the training points — the interpolation surface across pose, lighting, framing, scene; the extrapolation into compositions the dataset did not show.
A LoRA that fails the five tells has failed at the hard half. Its outputs may be visually accurate on training-adjacent prompts, but they are accurate by lookup, not by learning. We assert this is a definitional, not aesthetic, failure: such a model has not been trained to a useful endpoint. It has been trained past it.
4.4 Anchor in the published literature
This is not a novel position in spirit. Infusion's concept-agnostic overfitting (Zeng et al., 2024) [5] and Heng & Soh's open-world forgetting (2024) [4] both measure variants of exactly the failure we are naming. T-LoRA (Soboleva et al., AAAI 2026) [6] frames the tradeoff explicitly as one between identity fidelity and prompt-conditioned diversity. The contribution we are making is not the insight itself but the explicit, named, framework-level statement of it — combined with the five-tell diagnostic that operationalizes the criterion in a form a practitioner can read off a grid.
The field has, in effect, been arriving at this position one paper at a time without naming it. What this article adds is the consolidated statement: that generalization within the concept is the criterion these various failure-mode papers are collectively about, and that adopting it explicitly should change what practitioners ship as "finished" LoRAs.
5. Chained Training: A Methodology
This section describes the chained training schedule we use in our own work, the mechanism we believe accounts for its behavior, and the practitioner lineage it comes from. The paired-run result we observe under this methodology is reported in §6.
5.1 The recipe
Core hyperparameters at a glance; full configuration in Appendix A.
| Setting | Value |
|---|---|
| Base model | Qwen-Image (with dual text encoder, T5) |
| LoRA rank / alpha | 42 / 42 |
| Learning rate | 5e-5, AdamW8bit, EMA decay 0.99 |
| Noise scheduler | flowmatch |
| Precision | bf16 with qfloat8 quantization (model + text encoder) |
| Batch size | 1 (gradient checkpointing, no accumulation) |
| Resolution buckets | [512, 768, 1024] |
| Caption dropout | 0.35 (anime, 244 imgs) / 0.25 (linnea, 27 imgs) — only intentional variation between the two pairs |
| Sampling at inference | 45 steps, shift=7 |
| Trainer | ai-toolkit by Ostris (chained mechanism via external watchdog) |
| Hardware | NVIDIA RTX 6000 Ada (A6000, 48 GB VRAM) |
We apply this methodology to two paired runs at different scales, each training a distinct concept:
- Illustration — a 244-image dataset of mixed generative and hand-drawn imagery spanning ink, anime, digital, and print traditions. Trained as a style LoRA; published as Illustration 1.0.
- Linnea — a 27-image dataset of a novel hand-drawn character. Trained as a character LoRA at smaller scale to probe the methodology under tighter constraints.
Both share the hyperparameters above and use the same chained-schedule shape; they differ in dataset content, total step budget, and the per-phase step counts shown below.
A chained training run rotates through dataset subsets and then reintroduces the full combined dataset for a final consolidation phase. In our illustration training:
- Phase 1: train on subset 1 (28 images) from step 0 to step 9,000.
- Phase 2: switch to subset 2 (54 images), continue from step 9,000 to step 29,000.
- Phase 3: switch to subset 3 (58 images), continue to step 39,000.
- Phase 4: switch to subset 4 (110 images), continue to step 45,750.
- Phase 5: reintroduce the combined dataset (244 images), continue to step 59,000.
The four subsets sum to 250 images; the combined dataset is 244. Six images were removed during final curation before the combined dataset was assembled — quality-control cleanups, not intentional ordering. A minor confound on the cleanest data-ordering reading of the experiment, but not load-bearing.
Total training is comparable to a monotonic run on the combined dataset. The trainer saves checkpoints every 250 steps continuously across phases, so the dataset transitions can be inspected at the saved checkpoints around each boundary.
5.2 The mechanism — intentional forgetting as regularization
The intuition is straightforward. Each subset phase pulls the LoRA into a narrow region of parameter space committed to that subset's image distribution. Switching subsets forces a partial relearning that necessarily undoes some of the previous commitment. This is mechanistically reminiscent of catastrophic forgetting. We are not in a position to claim it is the same phenomenon formally, it does appear to behave similarly.
The full dataset reintroduction phase is a consolidation step. At this stage the LoRA must fit all of the subsets simultaneously. The only way to do that without exploding parameter norms is to find a region of parameter space that averages over the subset-specific commitments; a broader basin in the loss landscape, in the language of optimization theory.
This kind of mechanism has a published analog. Zhou et al. (ICLR 2022) [9] formalize the Forget-and-Relearn Hypothesis: intentional intermediate forgetting in connectionist networks acts as a regularizer that improves final generalization. Their experimental setup reinitializes weights between learning phases where we rotate data; the parameter-dynamics equivalence between the two is an open question we do not resolve here.
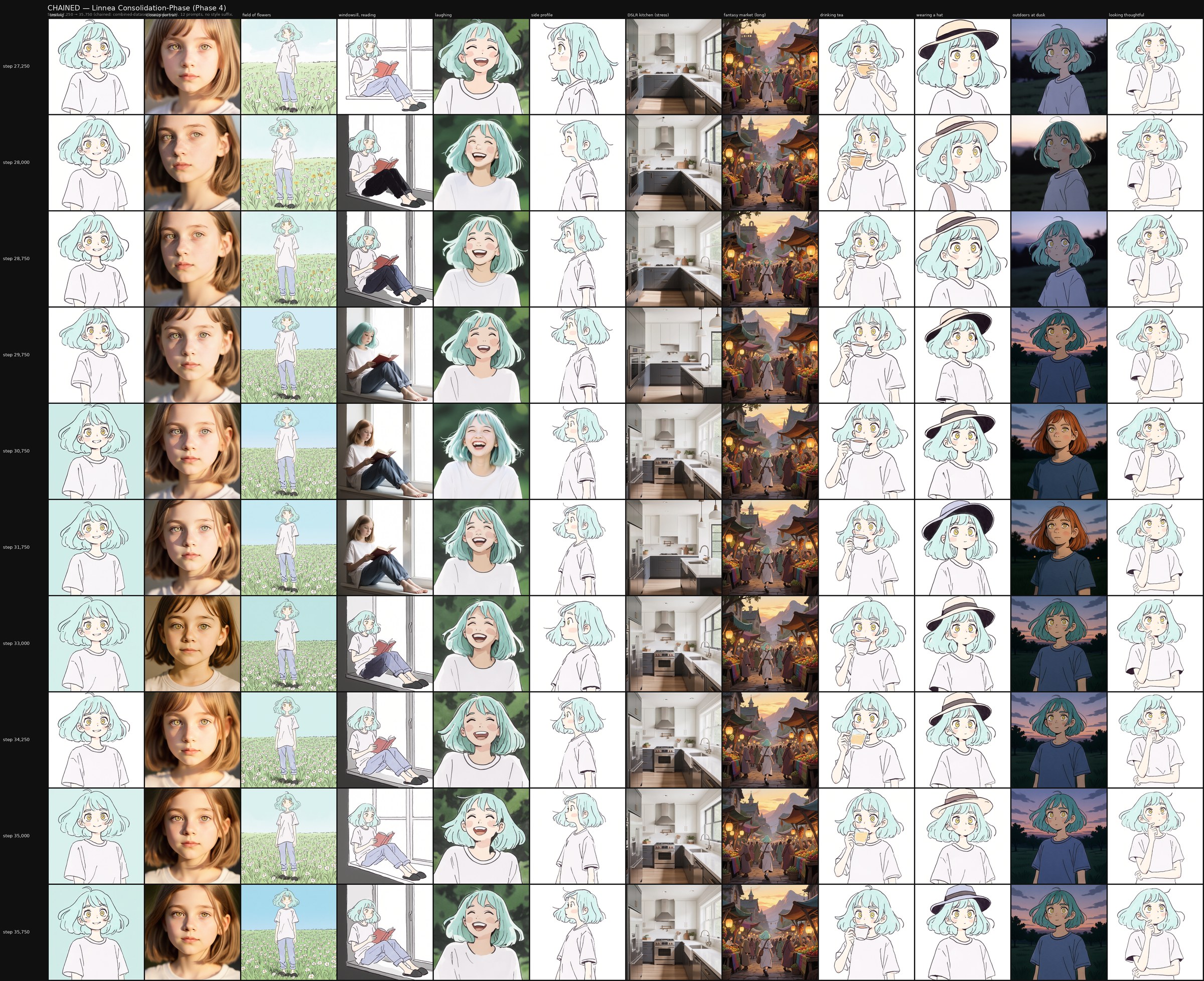
We have one direct probe of the consolidation phase: extending the linnea comparison grid through Phase 4 at dense checkpoint intervals (steps 27,250 → 35,750). Across that window, the chained model's output quality holds steadily — the consolidation phase neither sharpens convergence into a visibly different state nor degrades the model into combined-dataset overfitting. This rules out the failure mode where consolidation erases the methodology's earlier work, but it does not distinguish between two readings of the mechanism: a strong reading, in which consolidation actively averages the subset-specific commitments into a broader-basin solution, and a weaker reading, in which the chained model's intermediate-state advantage was largely set before Phase 4 began and consolidation merely preserves it. Distinguishing between these readings requires an experimental design our paired runs were not set up to deliver — for example, a matched-budget comparison of Phase 3-endpoint checkpoints against Phase 4-endpoint checkpoints. We flag this as an open question.
5.3 Distinction from prior published art
The closest published prior art:
- Forget-and-Relearn (Zhou et al., ICLR 2022) [9] — forgetting via weight reinitialization which functions under similar mechanisms.
- Curriculum learning (Bengio et al., 2009) [11] — orders examples by difficulty. The chained schedule orders by content domain, not by difficulty, which is a different ordering principle.
- Rehearsal / replay buffers (iCaRL, Rebuffi et al., 2017) [12] — replay past examples during new task training. The chained schedule does this as the final reintroduction phase.
We are not aware of a published formal analysis of the specific recipe — sequential dataset subsets with final combined reintroduction — applied to LoRA fine-tuning. The methodology lives in practitioner space rather than academic literature.
5.4 The regime we apply it to — and the limits we do not claim past
We apply this methodology in our own work on:
- Small datasets (under 300 images),
- Narrow concepts (single character or single style family),
- Content domains where the base model's prior is misaligned with the target and behaves in an overfit manner — hand-drawn illustration in particular.
The recipe described above reflects how we ran this training; it is not a fixed prescription. Smaller datasets train faster (the linnea character LoRA at 27 images completed in roughly a day rather than three), the chains can be shorter or longer, the per-phase step budgets can shift, and higher learning rates on shorter chains are an obvious thing to try. Whether four images in a four-phase chain produces a useful flexibility profile, or whether ten images in a two-phase chain does, are the kinds of variants we have not tested but think worth running.
5.5 What we observe about our chained model
The chained Illustration 1.0 LoRA, in our reading of its comparison grid, exhibits flexibility consistent with the five-tell diagnostic. Output variance across diverse prompts tracks prompt variance (Tell #2 mitigated). The no_lora baseline rows show that the LoRA's effect on off-distribution prompts is contained rather than catastrophic (Tell #1 mitigated). Adversarial stress prompts do not pull the trained style into unrelated contexts uncontrollably (Tell #4 mitigated).
The chained Linnea character LoRA, observed at the publication-grade checkpoint of step 35,000, exhibits flexibility consistent with the same diagnostic at a tenth of the dataset scale. Across the twelve diverse prompt columns of the v3 arc — portrait, full-body, scene, expression, and adversarial — the trained character renders as twelve distinct compositions rather than twelve variations on a fixed template (Tell #2 mitigated). The no_lora baseline row renders unrelated prompts at base-model quality, and the chained LoRA does not degrade those prompts at endpoint strength (Tell #1 mitigated). The adversarial photographic-kitchen column renders cleanly without the trained character leaking into the architectural interior (Tell #4 mitigated).
The parallel straight-baseline run we trained for comparison — described in §6 — also exhibits flexibility consistent with the five-tell diagnostic at a broadly similar level. Both runs produce competent generalizing models at the dataset scales we tested (244 images for the style LoRA, 27 images for the character LoRA). The differences we observe between the two runs are subtle rather than dramatic; we report them in §6 with appropriate epistemic care.
5.6 Prior practitioner lineage — this is not a new technique
The chained methodology is not new. It has roots in early Stable Diffusion 1.5-era practitioner trainers, most prominently TheLastBen's fast-DreamBooth Colab notebook (released within github.com/TheLastBen/fast-stable-diffusion, 2022) — colloquially known in the community as Dreambooth Colab. In that workflow, staged dataset handling was exposed directly in the UI: practitioners could swap datasets in and out between training segments as a first-class operation, and many did. What was rare was naming the practice as a methodology with research implications attached to it. Most users treated dataset swapping as a workflow convenience — switch in a refined subset for a few thousand steps, switch back, see what happened — rather than as the operationalization of an intentional-forgetting hypothesis.
The technique did not propagate forward as the field moved to SDXL, Flux, and beyond. Modern trainers (kohya-ss, ai-toolkit, OneTrainer, and the wider ecosystem) offer a much wider hyperparameter surface and far more configurability — but they do not expose mid-training dataset swapping as a first-class operation. Practitioners who want chained training in 2026 must reconstruct it manually, typically with external watchdog scripts that edit the trainer's config file at predetermined step counts. Our own runs in this article use exactly that approach. Chained training is not opposed by modern trainers — it is merely absent unless someone explicitly puts it back in.
The authors began LoRA training on Stable Diffusion 1.5 in 2022, where TheLastBen workflows were the entry point. Since then, chained or staged schedules have been applied whenever the trainer allowed it, across the majority of subsequently-released open foundation models plus several closed-source ones, spanning both character and style LoRAs at dataset scales from a few dozen to a few hundred images. Across that three-plus years of professional practitioner experience, qualitatively similar flexibility advantages have been observed.
The paired comparison in this article is the first formal A/B run the authors have set up with matched hyperparameters and identical sampling. The methodology is supported by three-plus years of anecdotal practitioner observation across concepts, models, and architectures. That is informal evidence, not benchmark evidence, but it is the substrate that motivated us to set up the paired run in the first place — and the substrate against which the results in §6 should be weighed.
6. Field Observations
6.1 Setup
We describe observations from two paired training runs and one grid review.
- Illustration 1.0 Qwen-Image LoRA (244 images, 5-phase chained schedule, 59,000 steps total): published as
alvdansen/illustration-1.0-qwen-image. - Illustration 1.0 baseline twin (same dataset, same hyperparameters, monotonic full-dataset training from step 0, 59,000 steps): published as
alvdansen/illustration-1.0-qwen-image-baseline. - Linnea character LoRA (27 images, 4-phase chained schedule, 35,750 steps total).
- Linnea character baseline twin (same dataset, same hyperparameters, monotonic full-dataset training from step 0, 36,000 steps).
Datasets. The anime style dataset is a assembled from a proprietary set of 244 curated illustrated images spanning the style range described in the published model card — clean cel-shading and 90s anime, European bande dessinée and graphic novel inks, lofi-style wide compositions, storybook watercolor, indie risograph print, retro gouache, atmospheric sci-fi gouache, and other illustrated traditions.
The linnea character dataset is 27 illustrated reference images previously published in past trainings of a single original character (mint-green hair, a recurring stylistic motif in Alvdansen's character work), spanning portrait, mid-shot, and full-body framings with varied poses, expressions, and clothing. We reproduce the full dataset below as a transparency figure.
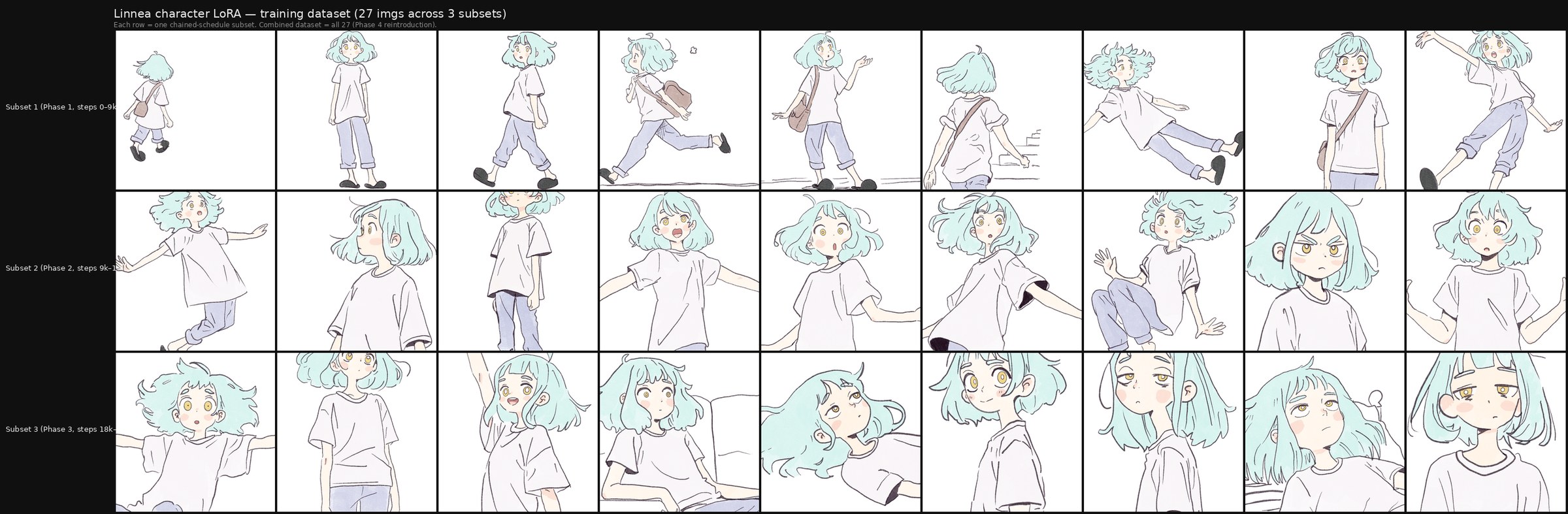
All grids were generated with identical sampling parameters: seed 42, 45 inference steps, CFG nominally 3.5 (note: Qwen-Image ignores classifier-free guidance scaling, so the CFG setting has no effect on this base model). Rows are checkpoints (a no_lora baseline at top plus eleven progression checkpoints sampled across the run, phase-aware and weighted toward Phase 4 for the linnea v3 arc). Columns are 12 diverse prompts curated to span the character-flexibility range (full set in the Prompt Glossary, Appendix D). The publication-grade linnea grid ends at step 35,000, selected from a dense consolidation-phase probe as the strongest defensible checkpoint. Each cell was rendered at 1024×1024 square; for the anime style runs we additionally rendered 768×1024 portrait and 1024×768 landscape variants.
6.2 What the chained model can do — the flexibility claim
This is the positive claim of the article's empirical section. We describe what we observe in the chained Illustration 1.0 LoRA across the five tells.
Tell #1 — Base capability degradation. The no_lora baseline row of the comparison grid renders prompts that do not invoke the trained style (a photographic stress prompt, for instance) at a quality and content consistent with the unmodified base model. When the chained LoRA is applied at its final checkpoint, those same no_lora-style prompts still render recognizably — the LoRA's effect is contained to prompts where its style cues are invoked, rather than imposing itself globally.
Tell #2 — Concept narrowing. Across the twelve diverse prompt columns in the linnea v3 arc, the chained LoRA produces twelve visibly distinct outputs at the late progression checkpoints. Output variance tracks prompt variance. The seed-variance test (unpacked in §6.3 with Figure 2 as the canonical instance) is the sharper version of this diagnostic and provides the cleanest A/B evidence in the paper.
Tell #3 — Caption rigidity. Paraphrase testing through the linnea v3 illustrated-suffix grid shows that the trained style holds across the suffix-on / suffix-off variants. The style fires from prompt content alone at the publication-grade checkpoint; it does not require the explicit style cue to engage.
Tell #4 — Entanglement leak. The p7_adversarial column (DSLR kitchen) renders without the trained character dominating at late chained checkpoints. The LoRA's concept is selectively activated by the prompt rather than imposed on every generation.
Tell #5 — Visual signature reproduction. Across the grid, we do not observe a recurring training-set artifact pattern that appears regardless of prompt content. Lighting, composition, and palette respond to the prompt's content cues rather than reproducing fixed signatures.
Together, these observations support our reading that the chained Illustration 1.0 LoRA generalizes within its trained range rather than memorizing into it. We frame this as the observation that anchors the article's quality-criterion argument empirically.
6.3 What the parallel straight-baseline run shows
We trained the straight-baseline run for comparison: identical dataset, identical hyperparameters, identical hardware, and a monotonic full-dataset training from step zero. Our reading of the paired comparison is more measured than we initially expected, and we report it that way:
Both runs produced competent LoRAs that pass the five-tell diagnostic without obvious failure on either side. The differences we observe are subtle. The chained run shows specific hints of flexibility advantages on stress-test diagnostics — seed-variance pose flexibility and prompt-length robustness — but the gap is not large enough to claim a methodological advantage from this experiment alone.
While we do not claim universal superiority of chained over monotonic training or that the experiment proves the methodology, we can observe that on these dataset scales (244 images, 27 images) on this base model (Qwen-Image), with this hyperparameter recipe, both training schedules produce competent results, and the chained schedule shows subtle hints worth following up on at scales more likely to surface a real difference.
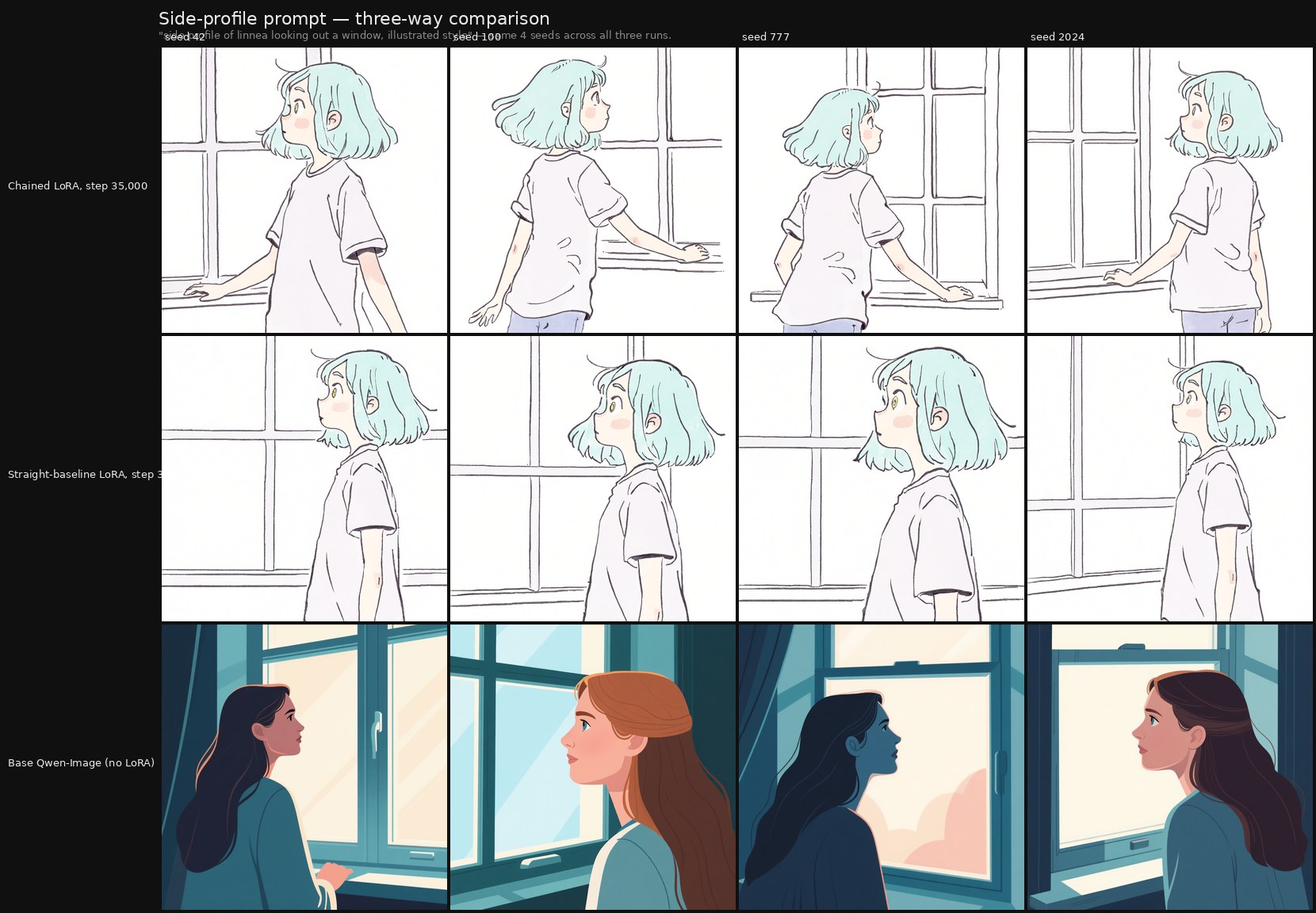
Specific observation — seed-variance: the cleanest Tell #2 finding in our data.
Following a suggestion from the broader practitioner community (notably Ostris, author of the ai-toolkit trainer we used), we ran a seed-variance test: the same four character-flexibility prompts rendered at the publication-grade checkpoint (step 35,000) of each linnea LoRA with four different seeds (42, 100, 777, 2024). The intent is to probe Tell #2 (concept narrowing) from a different angle than the progression grid does — varying random seed instead of varying prompt — so that mode collapse, if present, shows up as low output variance across the four seeds.
The result is the cleanest A/B separation we observe between the two runs.
On the "side profile of linnea looking out a window" prompt — a pose that appears in the training set, and that both LoRAs cling tightly to in the progression grids — the seed-variance test separates the two runs unambiguously. The chained LoRA produces four pose-distinct outputs across the seeds, varying angle, framing, and gaze while preserving the side-profile reading. The straight-baseline LoRA collapses to four near-identical outputs in essentially the same pose, drawn directly from a training-set image — a 2×2 of one shot. None of the other three character-flexibility prompts in the seed-variance test exhibits this pattern on either run: this is a prompt-specific collapse, surfaced only by the seed-variance diagnostic, and it is asymmetric between the two methodologies.
This is a textbook Tell #2 signature in the straight run that the chained run avoids on the same prompt with the same training data and the same total step count. Read at face value: at the publication endpoint, when both runs cling closely to a training-set pose, the chained schedule retains enough flexibility to vary the pose across seeds while the straight schedule does not. The seed-variance test is the diagnostic specifically designed to surface this distinction, and it surfaces cleanly here. We treat this finding as the strongest single piece of A/B evidence the paired comparison produces — not because it shows that chained training is generally better, but because it shows the methodology choice produces a concrete, measurable difference in flexibility at the regime where both runs would otherwise be called "competently trained."
Source file: seed-variance-output\_assembled\linnea_seed_variance.png (the linnea half of the regenerated seed-variance composite at step 35,000).
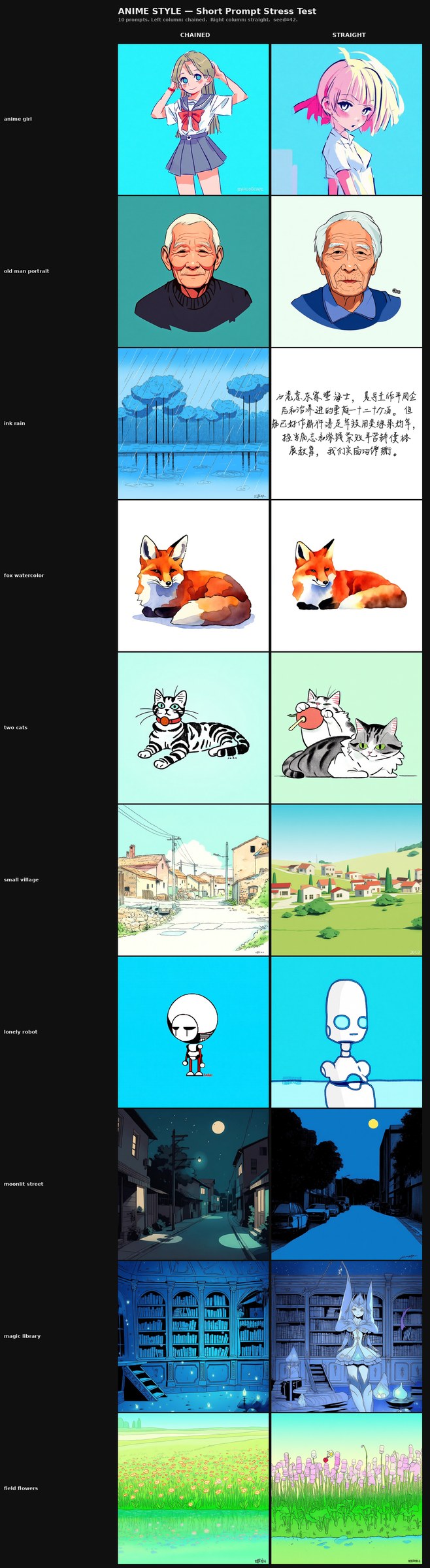
Specific observation — prompt-length stress test (Ostris-suggested follow-up).
Following a further suggestion from Ostris, we ran a four-grid prompt-length stress test pairing each LoRA against two prompt regimes — minimal 2–3 word prompts and paragraph-length context-heavy prompts. Ten prompts per regime per model. Full prompt sets are in Appendix D.
For the anime style LoRA:
- At paragraph-length prompts, both runs perform comparably. Detail responsiveness, composition, and palette adherence are visually similar across the ten long prompts.
- At 2–3 word prompts, however, the chained run holds together visibly better. The straight-baseline run begins introducing crude design elements — extraneous visual components in the composition that are not implied by the brief prompt and that do not appear in the chained outputs at the same prompts. This is consistent with a milder Tell #5 signature surfacing specifically under minimum-input conditions where the LoRA is forced to fill in from training-set priors and the straight run's priors are more rigidly bound to specific training-set images.
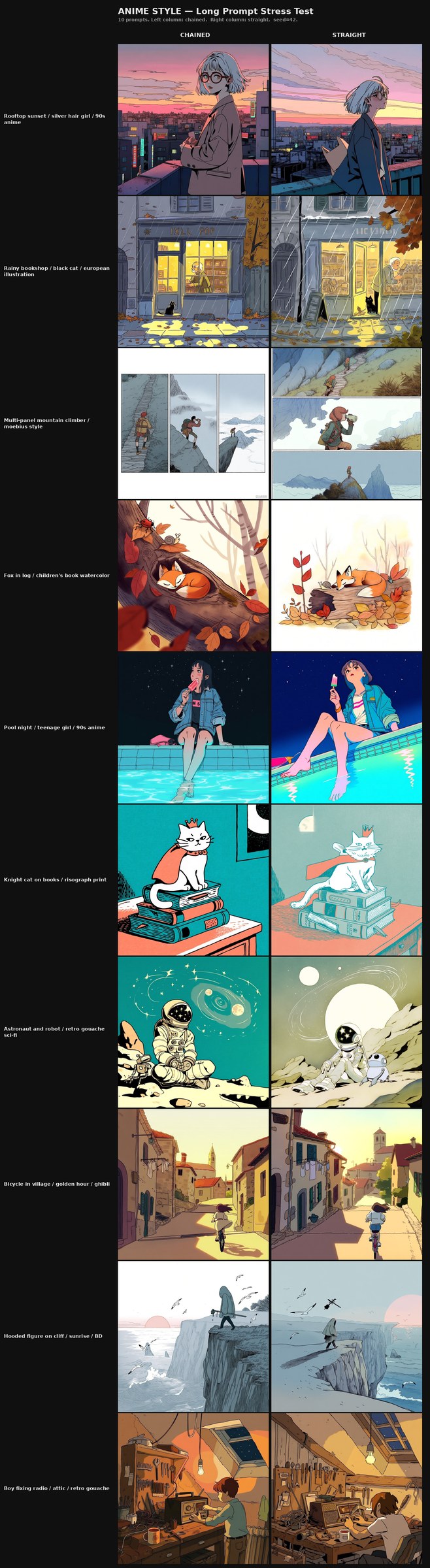
For the linnea character LoRA:
- At paragraph-length prompts, the chained run holds character consistency more reliably across the 10 scenes. The trained character renders as the same person in ten different long-prompt contexts at the chained's final checkpoint; the straight-baseline run shows pronounced unevenness across the same set — some poses come through very on-model for the training distribution, while others drift in character-defining features, with hair color drift the most visible signature of that unevenness.
- At 2–3 word prompts, both runs stay visibly close to their training data — not absolutely overfit, but pulled noticeably toward training-set compositions, poses, and framings. Crucially, each run shows different signs of that proximity: the specific shape of the training-data attraction is not the same between chained and straight, which suggests the two methodologies do not collapse identically when given minimal prompt information. We flag this regime — short-prompt generation on a 27-image character LoRA — as one where both methodologies produce results clearly bound to the training distribution but bound through different routes. The chained-vs-straight distinction here is qualitative (the signature of the proximity differs) rather than ordinal (one is not cleanly better than the other on this stress test).

The one regime where a clean ordinal comparison between the methodologies is least available is short-prompt generation on the small-dataset character LoRA: both runs hew closely to their training distributions there, through visibly different routes. We treat this as a useful boundary — it marks the regime in which the methodology choice produces differently-shaped near-overfit results rather than a clear win for either side, which is itself a constraint on what the methodology can be claimed to do.
Specific observation — base-model realism prior on portrait prompts (linnea, late checkpoints).
One prompt column in the linnea grid produces a different kind of failure from the others: the closeup portrait prompt (p2_closeup, "closeup portrait of linnea, soft warm light"). The no_lora baseline row of this column is fully photorealistic — a young woman, auburn-hair photo, soft natural light — which surfaces the underlying attractor: the combination of "closeup portrait" with "soft warm light" is densely associated with photographic editorial imagery in Qwen-Image's prior. Reading the column across progression checkpoints, both runs are pulled toward that attractor for most of training. At late checkpoints the chained run partially overrides — reaching an illustrated-style rendering with the trained mint-green hair color visible at step 35,000 — while the straight-baseline run stays closer to photorealism with brown/auburn hair, never fully crossing back to the trained style. This column therefore captures two observations at once: a base-model realism attractor on a specific prompt shape, and a chained-run advantage in eventually overriding that attractor where the straight-baseline run does not.
This is the empirical handle on the foundational-model bias hypothesis we introduced in §4.1. Realism-coded prompt elements (subject framing language, lighting language, lens language) can stack into a sudden style attractor that overrides downstream fine-tuning — a downstream-introduced bias in the §4.1 sense, surfaced here as a concrete observable. Whether this attractor pattern is general to Qwen-Image or specific to the portrait + warm-light combination is an open question; what we can claim is that, at endpoint LoRA strength on a 27-image character dataset, this particular prompt shape is the one we observe breaking through.

Broader observation — style-LoRA comparison.
Across the anime-style comparison grid, the two runs are also broadly competent and visually similar. We do not observe dramatic divergence in output variance or recurring signatures between the two; both runs respond to prompts with appropriate style variation across the full diagnostic prompt set. We report this honestly: the style LoRA comparison at 244 images does not, by itself, distinguish the two methodologies in a visually obvious way.


Read across all of the specific observations above — seed-variance side-profile pose flexibility, prompt-length stress responses in both runs, the base-model portrait-realism attractor that both runs inherit, and the broad style-LoRA comparison — a pattern emerges: the chained run is more even in its competence across the stress tests we have run, while the straight-baseline run shows pronounced unevenness on specific diagnostic prompts — seed-variance pose collapse on the side-profile prompt, crude short-prompt design elements in the anime LoRA, identity drift in long-prompt linnea generation — that the chained run does not exhibit on the same grids. This evenness-versus-pronouncedness pattern is consistent with what the chained methodology is mechanistically designed to produce: parameter commitments averaged across dataset subsets rather than over-committed to any single subset. We flag this as an observation worth pursuing in future tests rather than as a definitive characterization of either methodology.
The character-feature convergence finding from the linnea grid warrants a particular note. It is not the most visually striking difference in the grids — overall image quality is comparable between the runs — but it is the most diagnostically clean: it is binary (the color either converges or it does not), it is specific to a trained feature (so it cannot be attributed to base-model variation), and it shows up consistently across multiple progression checkpoints. We flag it as the example of the kind of finding the five-tell framework is designed to surface, even when broader qualitative inspection would call the two models "roughly equivalent." The hint exists; it is not strong enough at this dataset scale to be the article's empirical anchor.
What the experiment validates. Reading the paired runs in aggregate, the firmest empirical conclusion that both methodologies produce flexible, generalizing LoRAs at these dataset sizes on this base model, and that the hyperparameter recipe we use (rank/alpha 42/42, learning rate 5e-5, AdamW8bit, EMA decay 0.99, caption dropout 0.25–0.35 depending on dataset size, bf16 with FP8 quantization, 45 inference steps with the exact ComfyUI sigma schedule; full configuration in Appendix A) is viable for Qwen-Image small-dataset LoRA training. The methodology question — whether chained schedules produce meaningfully better results than monotonic ones — is not answered by this experiment. The answer requires a test designed to stress the methodology, not validate the practitioner.
6.4 The no_lora baseline row, specifically
The single most informative row in any of these grids is the baseline — the same 12 prompts rendered through Qwen-Image with no LoRA applied, sitting at the top of every v3 arc composite. The baseline row reveals three things at once: what the base model already does on each prompt without any fine-tuning, how much each LoRA shifts that, and (crucially) whether the shift comes at the cost of base capability on prompts the LoRA was not supposed to touch. It is the operational form of Tell #1 and the most direct check on whether a LoRA has degraded the model it was built on.
We recommend the no_lora row as a standard inclusion in any LoRA grid review. It costs one row of generation; it provides the single most expensive failure mode's diagnostic for free.
7. Limitations and Future Work
7.1 No quantitative head-to-head benchmark
The most obvious limitation. The paired runs were trained to be visually comparable, not to be benchmarked. Quantitative metrics for each of the five tells — CLIP-score variance across prompts as a Tell #2 metric, Color Drift Index (Heng & Soh, 2024) as a Tell #1 metric, output entropy measures as a Tell #5 metric — represent a natural upgrade path. We have not done this work and we flag it as the most important near-term follow-up if this methodology is going to graduate from position paper to evaluation paper.
7.1.1 The dataset sizes we tested do not strongly differentiate the methodologies
Closely related, and worth stating explicitly: a finding of this experiment is that 244 images (style LoRA) and 27 images (character LoRA) are both large enough on Qwen-Image that monotonic training produces a competent result. The cases where chained training is most likely to be visibly necessary — and where we have strong anecdotal practitioner reason to expect a meaningful gap — are smaller and more challenging datasets: under 20 images, narrower concepts, harder style domains where the base prior fights the target hardest. The opposite direction is equally worth exploring: a dataset with thousands of points could test whether the chained schedule continues to show flexibility advantages at scale, or whether the benefit dissolves once the monotonic run has enough data to recover the same generalization on its own. Both ends of the dataset-size axis are open empirical questions; the natural follow-up experimental program targets these regimes directly. We treat that program as the actual evaluation work this position paper is intended to motivate.
7.2 Single practitioner, n=1 paired pair
The methodology generalizes from one author's experience training and publishing LoRAs since 2022. The paired comparison itself is n=1. Future work should include multi-practitioner studies and multi-seed paired runs to separate practitioner-specific effects from methodology-specific effects.
7.3 Dataset-subset Forget-and-Relearn is not theoretically analyzed
The closest published prior art (Zhou et al., 2022) reinitializes weights between learning phases. We rotate data. Whether the theoretical guarantees of Forget-and-Relearn transfer to the dataset-subset rotation case is unproven. A direct theoretical analysis of parameter dynamics under dataset-subset rotation is open work.
7.4 Animation physics extension is speculative
Part 3 of this series intends to extend the framework toward video-LoRA training for hand-drawn animation physics. This is the most speculative leg of the program. The community has not solved animation physics in video LoRAs at all — even monotonic training does not consistently produce coherent squash-and-stretch, follow-through, or hand-drawn motion blur.
Our working hypothesis is that 2D animation physics — particularly squash-and-stretch and the broader family of exaggerated non-realistic motion — is impacted by the same misalignments that make hand-drawn illustration hard for diffusion models. The spectral-bias and VAE-compression arguments we laid out in §2.2 describe high-frequency spatial features fighting the denoising trajectory; 2D animation physics adds a temporal analog. Deformation patterns that depart from physical-realism priors (the way a body squashes on impact, stretches before springing, or trails secondary motion through follow-through) live in sharp frame-to-frame transitions that the video latent representation may strip the same way the image VAE strips fine line work. The video diffusion stack inherits both penalties at once: spatial high-frequency loss from the image VAE backbone, and temporal high-frequency loss from whatever temporal compression the video model adds on top. Whether the chained methodology helps here in the way we suspect it helps for spatial hand-drawn content — by preventing narrow commitment to specific motion templates through subset rotation — is genuinely unknown and we flag it as such. Part 3 is the experiment that opens this question rather than answers it.
7.5 Cross-model generality
Part 2 of this series will examine the same thesis under additional base model architectures. Whether the chained-vs-monotonic advantage we observe under Qwen-Image holds under different base model architectures is an open empirical question we are actively investigating.
8. Related Work
Continual learning ancestry. Catastrophic forgetting in connectionist networks (McCloskey & Cohen, 1989 [18]; French, 1999 [19]) is the original framing of the phenomenon we operationalize as Tell #1. Rehearsal-and-replay (iCaRL, Rebuffi et al., 2017) [12] and episodic memory approaches (GEM, Lopez-Paz & Ranzato, 2017) [13] are the closest continual-learning analogs to the dataset-subset reintroduction phase of the chained schedule. Zhou et al.'s Forget-and-Relearn Hypothesis (ICLR 2022) [9] is the article's direct theoretical anchor.
Diffusion fine-tuning. DreamBooth (Ruiz et al., 2022) [8] is the foundational small-dataset diffusion fine-tuning method and the source of the prior-preservation insight that anchors our generalization-as-quality position. Textual Inversion (Gal et al., 2022) [14] and Custom Diffusion (Kumari et al., 2023) [15] are adjacent. LoRA itself (Hu et al., 2021) [16] is the substrate of every method discussed in this article.
LoRA overfitting mitigations (2024–2026). T-LoRA (Soboleva et al., AAAI 2026) [6] explicitly addresses LoRA overfitting via timestep-aware training. AutoLoRA (Zhang et al., 2024) [7] addresses it via automated rank selection. Infusion (Zeng et al., ACM MM 2024) [5] introduces the concept-agnostic / concept-specific overfitting distinction that we adopt as the academic name for Tells #1 and #2. ConceptGuard (Guo & Jin, CVPR 2025) [10] addresses concept entanglement. Open-World Forgetting (Heng & Soh, 2024) [4] formalizes and measures Tell #1 with the Color Drift Index.
Curriculum and staged training. Bengio et al. (2009) [11] introduce curriculum learning, ordering examples by difficulty. The chained schedule we describe is a curriculum variant ordered by content domain rather than difficulty.
Practitioner lineage (informal but verifiable). TheLastBen's fast-DreamBooth Colab (github.com/TheLastBen/fast-stable-diffusion, 2022) is the most prominent SD 1.5-era trainer in which staged dataset handling was structurally inherent. Modern trainers (kohya-ss, ai-toolkit, OneTrainer) do not encode staged training structurally; community guidance on CivitAI from the 2022–2023 era often referenced staged approaches without naming them as such, and that lineage did not propagate forward into newer-base-model community guides to the same extent. We acknowledge this as practitioner history, not formally published prior art, and frame it as the verifiable lineage of the technique we surface rather than as academic precedent.
This survey is not exhaustive. We focus on the works most directly informing the thesis and the five-tell framework. A more comprehensive related-work survey is appropriate for an eventual full evaluation paper that follows this position paper.
9. Conclusion
We have argued four things, at four distinct epistemic levels.
1. Generalization within the trained concept is the right quality criterion for small-dataset LoRA fine-tuning. The five tells we outlined earlier are a diagnostic framework for identifying when a LoRA has overfit into memorization. We draw on established literature in concept-specific overfitting, open-world forgetting, and prior-preservation. We invite the LoRA training community to apply the five-tell framework when evaluating their own models, and to share counter-evidence where it does not hold.
2. The chained dataset methodology, applied under the hyperparameter recipe described in Appendix A (rank/alpha 42/42, learning rate 5e-5, AdamW8bit, EMA decay 0.99, caption dropout 0.25–0.35 dataset-size dependent, with FP8 quantization on Qwen-Image), produces a competent, generalizing LoRA at both the 244-image style scale and the 27-image character scale.
3. In the paired comparison we describe, both runs pass the five-tell diagnostic without obvious failure on either side. We do observe specific signals that the chained model has flexibility advantages over the straight-baseline run at this regime — most concretely, a clean Tell #2 (concept narrowing) distinction on the seed-variance side-profile prompt, where the straight LoRA collapses to a 2×2 of one training-set pose while the chained LoRA produces four pose-distinct outputs under the same prompt and seed budget. We also observe more consistent convergence on character-defining features in the v1 portrait grid (the trained hair color). Both findings are concrete and reproducible from the included composites; neither alone is dramatic enough to claim a general methodological advantage at this dataset scale. We treat them as hints, not proofs. The chained schedule is at least on par with the monotonic baseline across the diagnostic set, and shows specific, prompt-localized advantages where the diagnostic is designed to surface them; whether it is meaningfully better in general requires test conditions designed to stress the methodology rather than validate the recipe.
4. The natural next step is to test the chained methodology at dataset sizes and concept difficulties that are more likely to expose monotonic training's failure modes — datasets under 20 images, narrower concepts, harder style domains where the base model's prior fights the target most. Those are the conditions in which our anecdotal practitioner experience suggests the chained advantage is most visible; they are the conditions under which the methodology should be evaluated, not validated. We treat the experiments described here as the baseline-quality check that lets us proceed to the harder tests, rather than as the test of the methodology itself.
This is Part 1 of a multi-model series. Part 2 will examine the same thesis under additional base model architectures and at scales more likely to differentiate the methodologies. Part 3 will extend the framework toward hand-drawn animation physics in video LoRAs. The five-tell framework and the generalization-as-quality position do not depend on the outcome of those follow-up tests; the chained-methodology question does, and we are honest about that.
Appendices
Appendices A–D summarize content whose full form lives in the markdown source. Appendix E (Figure & Composite Inventory) follows expanded with inline thumbnails.
Appendix A — Training Configuration (click to expand)
Four runs documented: chained + straight-baseline pairs at two dataset scales (anime style 244 imgs, linnea character 27 imgs). Common hyperparameters across all four: rank/alpha 42/42, batch size 1, AdamW8bit, lr 5e-5, EMA decay 0.99, flowmatch noise scheduler, bf16 with qfloat8 quantization, resolution buckets [512, 768, 1024].
Per-pair variation:
| Setting | Anime style (244) | Linnea character (27) |
|---|---|---|
caption_dropout_rate | 0.35 | 0.25 |
| Total steps (chained) | 59,000 / 5 phases | 35,750 / 4 phases |
| Total steps (straight) | 59,000 monotonic | 36,000 monotonic |
| Wall-clock | ~70 hours | ~24 hours |
The caption-dropout difference is intentional: the smaller linnea dataset would lose proportionally too many gradient signals at 0.35 dropout. All other hyperparameters are identical across both pairs. Full YAML and dataset schedules in signe-article-lora-position-paper.md Appendix A.
Appendix B — Grid Methodology (click to expand)
Comparison grids use identical sampling parameters: seed 42, 45 inference steps, exact ComfyUI sigma schedule with shift=7, LoRA strength 1.0. Rows are checkpoints; columns are prompts. The publication-grade linnea v3 arc spans 12 phase-aware checkpoints (0, 4,500, 9,250, 13,500, 18,250, 22,500, 27,250, 28,750, 30,000, 31,750, 33,500, 35,000), weighted toward Phase 4 where the consolidation mechanism plays out. Full enumeration in signe-article-lora-position-paper.md Appendix B.
Appendix C — How to Read the Five Tells in a Grid (click to expand)
Tell #1: no_lora row vs. LoRA rows on prompts unrelated to the trained concept. Tell #2: prompt-diversity columns at a late checkpoint, or seed-variance test at a fixed prompt. Tell #3: paraphrase variant grid. Tell #4: adversarial column in unrelated context. Tell #5: inspect for recurring signatures across prompts that should not share them. The grid is the diagnostic.
Appendix D — Prompt Glossary (click to expand)
Full prompt sets for every grid referenced in §6 are listed in the markdown source (D.1–D.10). All generations used seed 42 unless otherwise noted; the seed-variance test rotates through 42 / 100 / 777 / 2024.
Appendix E: Figure & Composite Inventory
Every assembled composite used to support the article, with source path and a short description. Inline figures from §6 are listed first in figure-number order; additional reference composites (full grids that the focused figures were extracted from, plus historical artifacts) follow.
Figures referenced inline
Additional reference composites (not inlined in §6)




, illustrated style appended to each prompt. Companion variant; trained style holds across both suffix-on and suffix-off conditions at endpoint.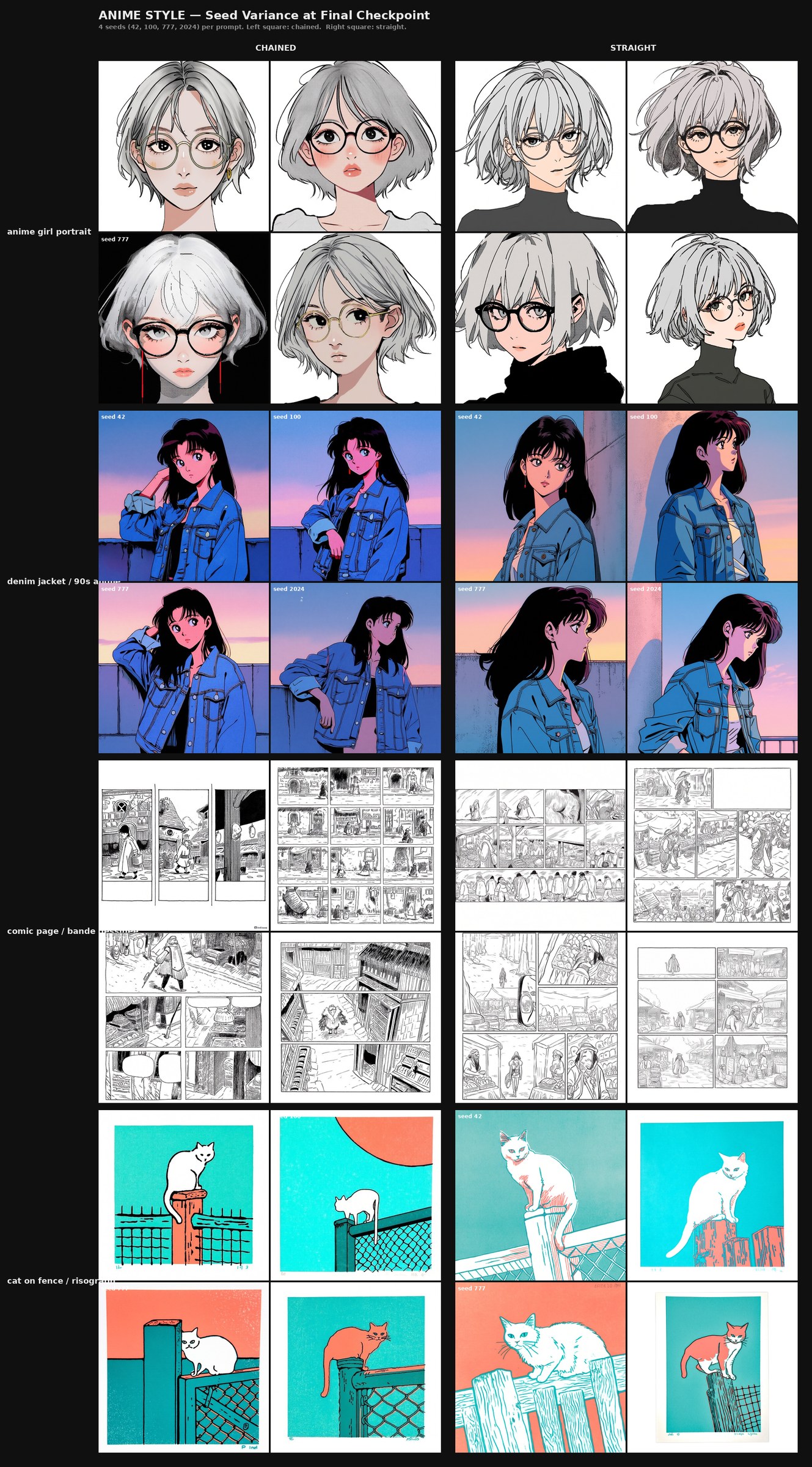


_old/ as the source data for §5.2's mechanism discussion).
